We Tested 3 Frontier Models on Bengali Linguistics: They Rarely Agreed

Sebastian Liu, Krishna Rupaakula, Sandeep Chinchali, LJW
February 24, 2026
Bengali is spoken by over 280 million people, making it one of the most widely spoken languages in the world. Yet it represents less than 0.1% of all web content. When AI models learn language, they learn from the internet. And the internet has very little Bengali to teach them.
This would be a problem for any underrepresented language. But Bengali makes the challenge especially hard. West Bengal and Bangladesh maintain separate orthographic standards. The language has at least five major dialect groups, some so divergent that their classification as separate languages is debated. Spoken forms regularly differ from written standards. There is no single "correct" Bengali. Unlike English, where you can scrape the web and get a fairly consistent picture of the language, Bengali requires data that captures dialectal variation, regional norms, and the gap between how people speak and how people write. That data doesn’t exist on the open internet at scale. It has to be sourced directly from the physical world.
We ran an experiment to find out just how wide this gap is today.
We gave GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro the same set of Bengali transcripts and asked each to identify errors. Native Bengali linguists reviewed a subset as a human baseline. You might expect some disagreement on edge cases. You'd probably expect the models to mostly agree on what's an error and what isn't.
They didn't. Not even close.
Experiment Design
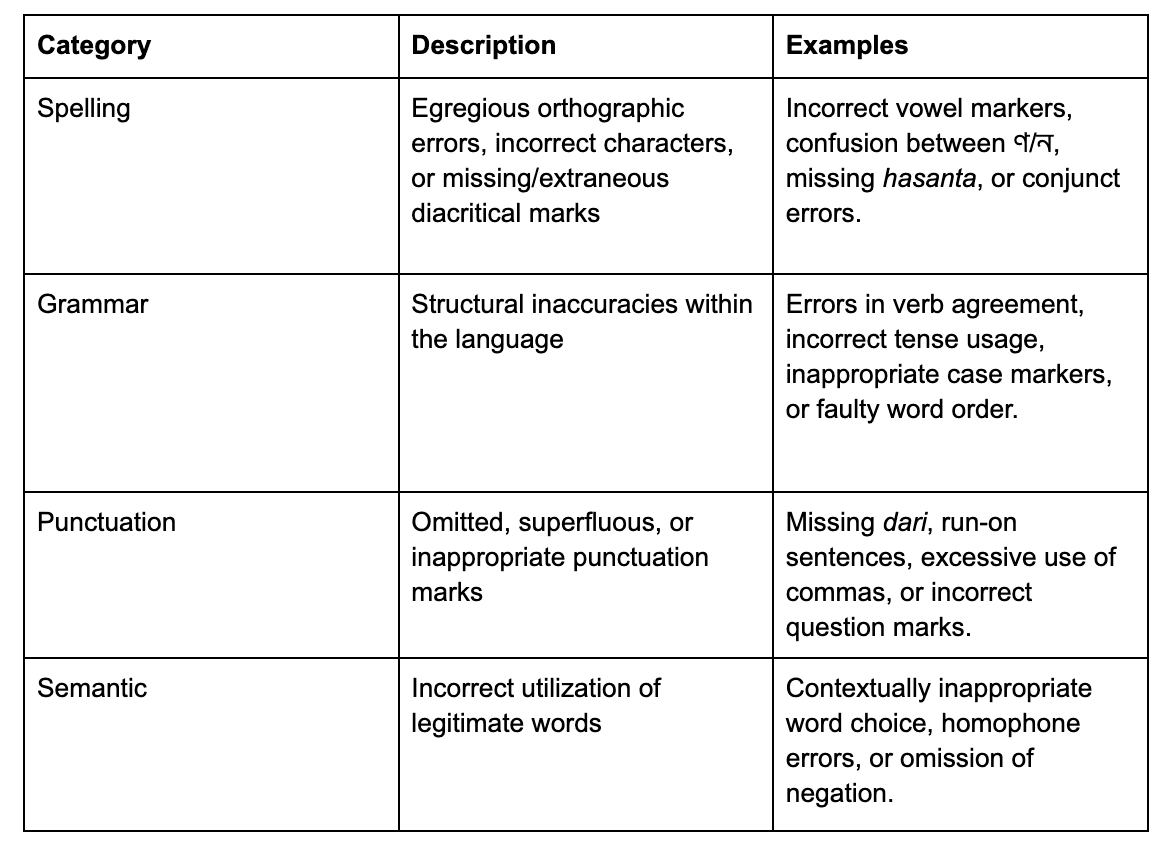
Each model received the same 160 Bengali transcripts and the same prompt: identify spelling, grammar, punctuation, and semantic errors according to standard colloquial Bengali as used in Kolkata, West Bengal. Native Bengali linguists independently reviewed a subset of 40 transcripts to establish a human reference for what actually counts as an error. Both human reviewers and models worked from the same four-category error taxonomy:
Finding 1: The Models Don't Agree on What Counts as an Error
Across 160 transcripts, the three models flagged a combined 2,407 errors. But more than half of those, 53.8%, were identified by only one model. Just 13.5% of errors had all three models in agreement.
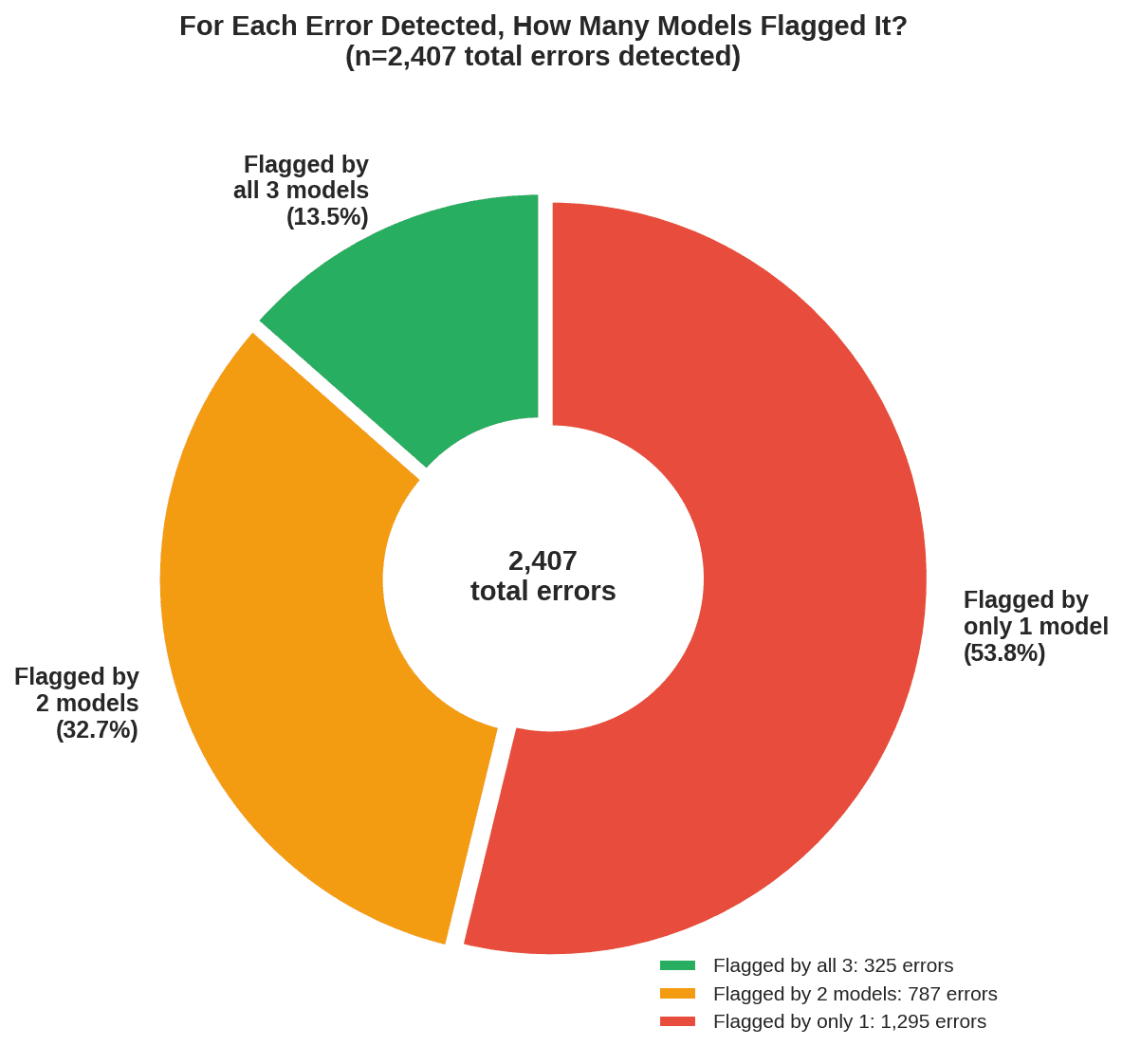
The three-way agreement was rare. But what about any two models agreeing? Even the best-performing pair, Claude and Gemini 3 Pro, overlapped on only 23.1% of detected errors.
Model | Total Errors | % Unconfirmed by Other Models |
|---|---|---|
GPT-5.2 | 796 | 59.5% |
Gemini 3 Pro | 664 | 43.1% |
Claude Opus 4.5 | 504 | 35.1% |
Finding 2: Models Also Miss What Native Speakers Catch
Disagreement between models is one thing. But how do they compare to native Bengali speakers?
On the 40-transcript subset reviewed by both linguists and models, the results were stark. The best individual model, Gemini 3 Pro, caught only 30.8% of the errors that human reviewers identified. Even combining all three models only reached 40.8% coverage. The majority of errors that native speakers found were invisible to every model.
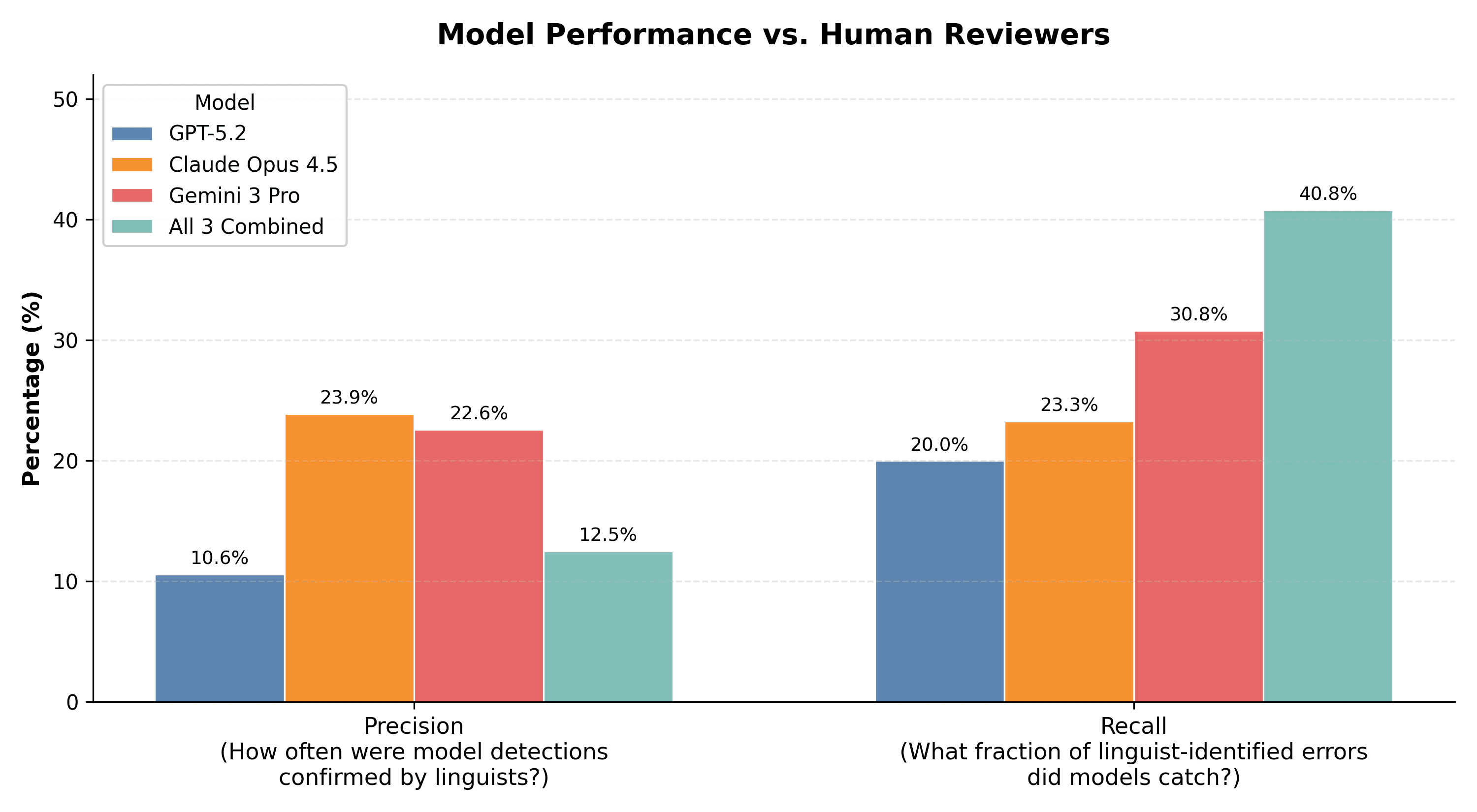
Precision was just as concerning. Only 12.5% of what the models collectively flagged matched what human reviewers found. Put differently: 7 out of every 8 model-detected "errors" had no human confirmation.
The models aren’t slightly off, they're operating with a different picture of what correct Bengali looks like than the people who actually speak it.
Finding 3: More Detections Don't Mean Better Detections
If models disagree this much, does flagging more errors at least correlate with catching the right ones?
No. GPT-5.2 identified the most errors of any model, 796 total. But 59.5% of those weren't confirmed by any other model. It also had the lowest precision against human annotations at 10.6%, compared to 22-24% for Claude and Gemini.
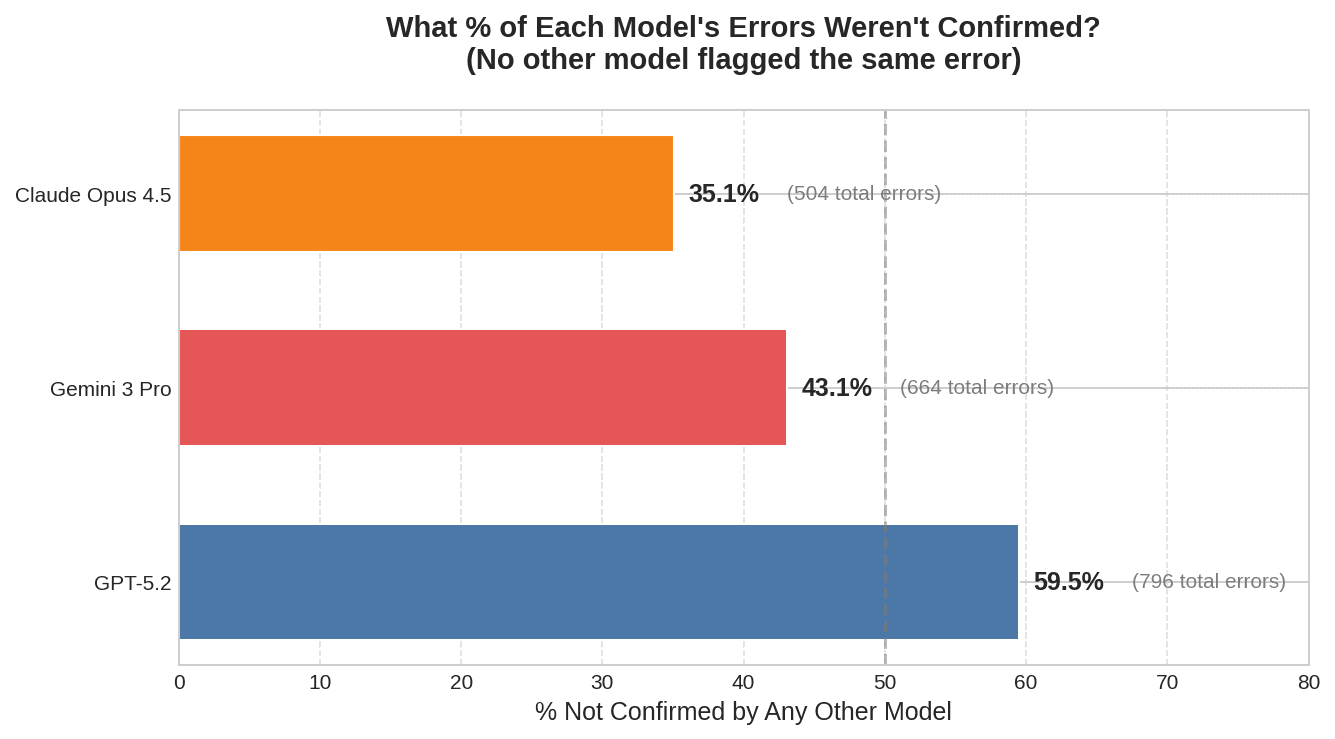
On the other end, Claude Opus 4.5 flagged the fewest errors but had the highest confirmation rate. Quantity isn't quality, and in a domain where the "right answer" is genuinely ambiguous, confidence without consensus is noise.
A Closer Look at the Errors
The numbers tell one story. The actual examples tell a sharper one. Here are a few cases from the data that show what these disagreements look like in practice.
All three models missed what native speakers catch instantly. In one transcript, the phrase ব্যাংক অ্যাকাউন্টে অ্যাক্সেস নেই (“there is no access in the bank account”) appeared with an incorrect case marker. The correct form is অ্যাকাউন্টের, with the possessive ending র, meaning “access to the bank account.” Without it, the sentence is grammatically wrong. All three models missed it. As our linguist noted, the models appear unable to identify that the lack of a single possessive word ending makes the sentence ungrammatical. A basic error any native speaker would catch on first reading.
Three models marked correct Bengali as wrong. Three models flagged কি in the phrase আমি কি করে (“How do I?”) as an error, correcting it to কী. But কি and কী serve different grammatical functions: কী is used when asking about a specific thing (“what”), while কি is used when asking about manner (“in what way”). In this context, কি was correct. The models applied a blanket conversion, treating every কি as a misspelling of কী, without understanding a distinction that is basic to Bengali grammar.
GPT-5.2 preferred formality over correctness. GPT-5.2 flagged করেছো (“have done”) as an error, correcting it to করেছ, a more formal variant. No other model or human reviewer agreed. Both are accepted spellings in colloquial Bengali, but as our linguist noted, the models appear trained to prefer the more formal version. When that preference gets applied at scale across hundreds of detections, the result is a high detection count driven by formality bias rather than genuine errors.
The models did not share the same understanding of dialect. One transcript used the word পানি for "water." As our linguist noted, জল is the standard word for water in West Bengal based dialects, while পানি is more commonly used in Dhaka and other East Bengal based dialects. We asked all three models to check against the Kolkata standard. Claude Opus 4.5 and Gemini 2.5 Pro correctly identified পানি and changed it to জল. GPT-5.2 did not. Despite receiving the same instructions, the models did not share a consistent understanding of the difference between Kolkata and Dhaka Bengali.
So What: It Isn’t a Model Problem, It’s A Data Problem
Digging further, when all three models did agree that something was an error, they agreed on the correction 100% of the time. The models aren't struggling with how to fix Bengali errors. They're struggling with whether something is an error at all.
The models' disagreements suggest they've each internalized different norms for what correct Bengali looks like, norms shaped by whatever fragmented Bengali data happened to be in their training sets. When three frontier models can't agree on what counts as an error, the AI tools built for those 280 million Bengali speakers inherit that disagreement. When they catch less than half of what native speakers find, those tools inherit the blind spots too.
And this is just Bengali. There are hundreds of languages where the same dynamics apply, each with its own dialects, orthographic debates, and gaps between spoken and written forms.
The specific errors will differ, but the underlying problem is the same: models trained on insufficient data produce inconsistent results for the communities that need them most. Closing this gap requires training data that captures the full complexity of these languages, and that data has to come from the native speakers these tools are meant to serve.
This isn’t a model problem, it’s a data problem.
Data from January 2026. Models: GPT-5.2, Claude Opus 4.5, Gemini 3 Pro. 160 Bengali transcripts reviewed by all three models; 40 independently reviewed by native Bengali linguists.
Acknowledgements: The authors would like to thank Rashmi Nagpal and Emma Joelle for their contributions to the piece.